

Posted on 1 December 2022, updated on 26 July 2023.
A cloud-agnostic autoscaling solution
The catchphrase of this tool states: “Just-in-time Nodes for Any Kubernetes Cluster”. What can we understand from this?
Instead of trying to guess, let’s extrapolate from their nice drawing:
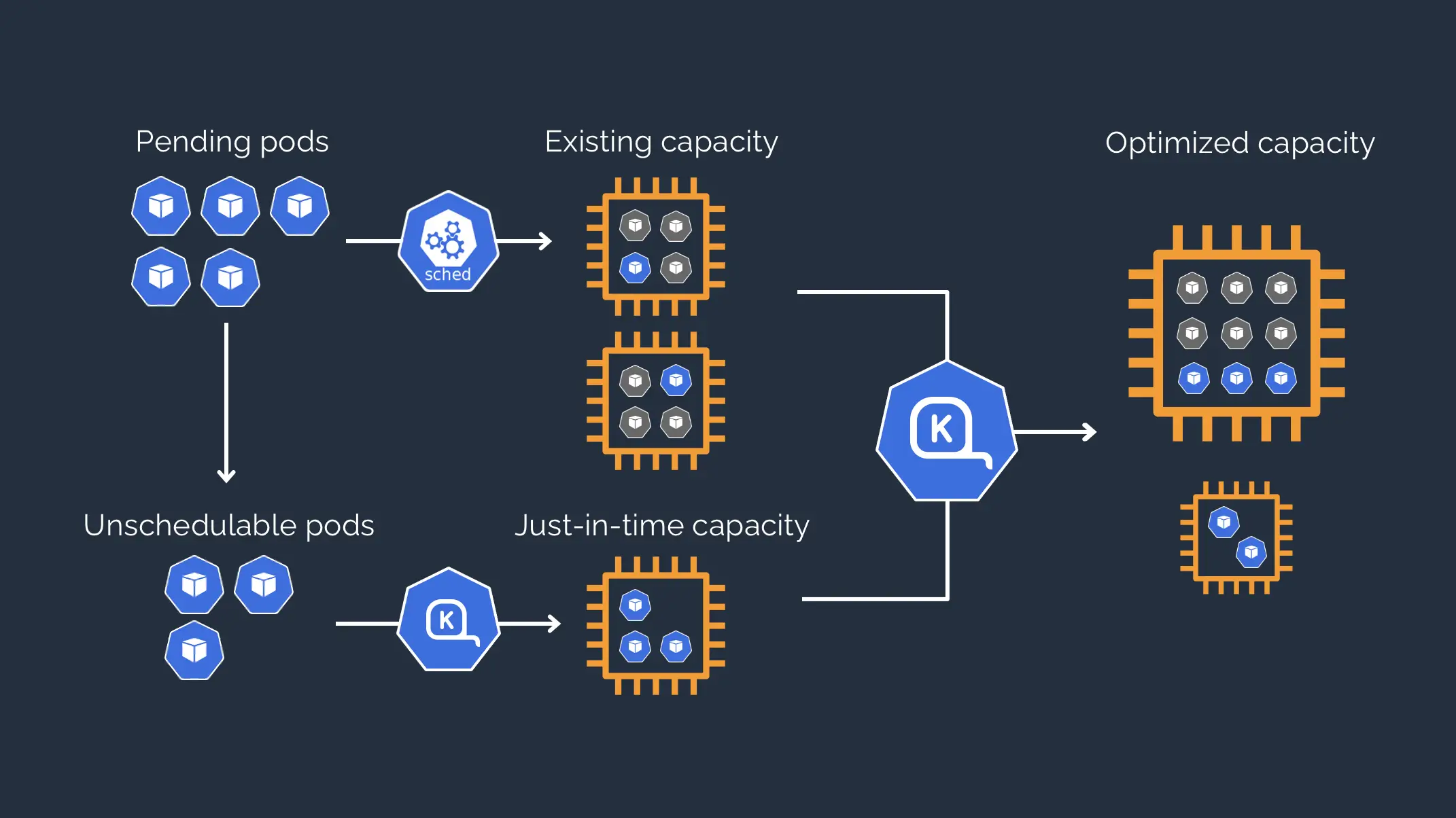
It all begins with pending pods. A pod is in the “pending” status when it appears in the cluster and is not yet affected to run on a node. There are two outcomes to this situation:
- The pod is schedulable on a node: the Kubernetes scheduler takes the lead and places the pod on a node matching the pod’s requirements
- The pod is unschedulable: the scheduler hasn’t been able to find anywhere to place the pod, and it stays in a pending state
A pod can be unschedulable for a variety of reasons, including the most common:
- The pod does not tolerate any taints that the nodes possess
- There is no node matching the pod’s node selector
- The combined resources (CPU or memory for example) requested by the pod are too high for any existing node
- There is an architecture mismatch between the container(s) contained by the pods and the nodes (for example, ARM containers cannot run on x86-64 nodes for example)
All these reasons can add up.
In that case, the pod is stuck and will never run! But not so fast, Karpenter is here to save the day💪
Its main job will be to:
- Evaluate the autoscaling needs of each and every unschedulable pod
- Compute the most optimized way to increase the cluster’s size with new instances, while matching the evaluated autoscaling needs
- (this is the just-in-time nodes part of the catchphrase)
- Contact the cloud provider to create the necessary instance(s) which will join the cluster
- (this is the “any kubernetes cluster” part of the catchphrase)
- Schedule all the pending pods to the new instances
This is all done by using the configuration specified in provisioners. It’s a custom resource deployed when installing Karpenter which specifies all the provisioning configurations of your cluster. With this resource, you can define distinct node sets, each with its own characteristic. For example, you could define a provisioner which only creates ARM nodes, or nodes with a ci-cd label to handle CI/CD jobs that run into your cluster.
Apart from this, Karpenter has some side hustles to make sure that your cluster is optimized to your liking:
- It adds a finalizer to all the nodes it manages so that when a node is deleted from the cluster, all of its pods are drained and the instance is terminated before disappearing
- You can configure a time-to-live on your nodes so that after a determined duration, the node is deleted
- It can enable the continuous upgrading of your node images with the right configuration
- If a node becomes empty (when the last non-daemonset pod leaves the node), Karpenter will delete it after a delay that you can adjust
- You can enable a consolidation feature that will aim to reduce the cost of your cluster by simulating node deletions and trying to replace instances with cheaper alternatives if available
Kubernetes Cluster Autoscaler comparison
The main alternative to Karpenter is the classic Kubernetes Cluster Autoscaler.
Kubernetes Cluster Autoscaler is a tool released in 2017 that has been used extensively across many infrastructures whereas Karpenter is newer.
Both of these autoscaling tools must be installed inside your cluster, but they differ in the way they interact with the cloud provider. We will solely focus on AWS in these examples as it’s currently the only fully integrated cloud provider for Karpenter.
Here’s a drawing that will help you differentiate the setup of an AWS EKS cluster with Kubernetes Cluster Autoscaler and Karpenter:

The Kubernetes Cluster Autoscaler needs AWS EKS managed node groups to work properly. In a nutshell, managed node groups are an abstraction over AWS Autoscaling groups. They allow for the configuration of Kubernetes-specific properties, like labels or taints, on EC2 instances.
Kubernetes Cluster Autoscaler interacts directly with the Autoscaling group service to adjust capacity. This means that if you use Infrastructure as Code tools like Terraform, modifying your cluster configuration will mostly require updates in your Terraform code rather than the Kubernetes Cluster Autoscaler’s parameters.
The consequence of this is that your Kubernetes cluster’s state is closely tied to the cloud provider you are using, AWS in this instance. This can be positive in the sense that you will benefit from the additional features that managed node groups bring.
By using managed services, you will also have a better view of your overall cloud infrastructure by separating all the applicative parts (what’s inside the Kubernetes cluster) from all the gears supporting it (all the infrastructure as code).
Karpenter simplifies this setup by only interacting with the EC2 service. All the autoscaling configuration is specified in provisioners, which can be regarded as a more configurable alternative to EKS-managed node groups.
Here are the key comparison points between both autoscaling solutions:
Karpenter’s strengths:
- If you don’t know or don’t have any requirements for the instance types that you need, Karpenter will make the choice for you, you only need to create a provisioner with the minimum parameters’ requirements
- Managing autoscaling in Kubernetes allows for much more flexibility than using on-managed node groups with Terraform. We generally use Terraform to deploy static infrastructure whereas autoscaling in Kubernetes is dynamic, therefore it’s more convenient with Karpenter.
- Provisioners, as Kubernetes resources, are much more flexible than EKS managed node groups (for example, instance types is an immutable parameter on managed node groups, not on a provisioner)
- You can define Kubernetes-specific constraints for provisioners, like CPU count, memory limits…
- Node scheduling does only depend on one service (EC2) instead of autoscaling groups for the Kubernetes Cluster Autoscaler, which is less responsive
- Scaling a managed node group from and to 0 is a pain when using Kubernetes Cluster Autoscaler, there is no such problem with Karpenter
Karpenter’s weaknesses :
- It’s still tied up to AWS at the moment, with not much visibility for future cloud provider integrations
- You still need a managed node group to deploy Karpenter on, it’s not possible to entirely rely on Karpenter for your node management
- The separation between infrastructure and applications in your Kubernetes cluster becomes blurrier
Deploying Karpenter
Now that you’re convinced that using Karpenter will better suit your scaling needs than Kubernetes Cluster Autoscaler (or not, let me know!), we will see how to deploy and configure it for a quick start setup.
We will only focus on the deployment of this tool on AWS because of the reasons stated previously.
Deployment
For the first part of the deployment procedure, I highly recommend following the official “Getting started using Terraform” guide (change the docs to the latest version). It will help you set up the AWS resources (network, cluster, IAM) from scratch. Follow it until you finished the “Create the KarpenterController IAM Role” section.
If you already have your infrastructure, here are the key points that you will need to handle :
- add all the AWS IAM resources
- make sure that you can use IAM role with service accounts in your EKS cluster
- add specific tags on your AWS subnets and security groups that will be used by provisioners later
Next, install Karpenter using Helm, here are the two files that you’ll need:
# Chart.yaml
apiVersion: v1
name: karpenter
description: A deployment of karpenter
type: application
version: 0.1.0
dependencies:
- name: karpenter
repository: https://charts.karpenter.sh
version: 0.16.3 # Tip : replace with the latest version# values.yaml
karpenter:
aws:
defaultInstanceProfile: "" # Name of the Karpenter IAM instance profile
clusterEndpoint: "" # HTTPS endpoint of your cluster API
clusterName: "" # Name of your EKS cluster
serviceAccount:
annotations:
eks.amazonaws.com/role-arn: "" # ARN of the Karpenter IAM roleThe install command should be :
# Download the chart locally
helm dependency build
# Install a Helm release of Karpenter
helm install -n karpenter --create-namespace=true karpenter . Now, you should have a Kubernetes cluster with a Karpenter pod running inside of it, let’s configure it so that it can add new nodes.
I would give the deployment process a mark of 4.5/5 because the deployment process in Kubernetes is really simple. There are some steps to set up IAM on AWS which are required and make it a bit harder, but it’s fine.
Configuration
Configuring autoscaling with Karpenter will involve two types of resources: providers and provisioners. We will see first how to deploy a simple provider which will handle the configuration for all subsequent provisioners.
Providers
Providers are cloud provider-specific resources that define parameters that will be used by provisioners. In our case (AWS), a provider will be an AWSNodeTemplate resource that will handle EC2 instance configuration. You can see all the available fields for AWSNodeTemplate on Github, or use the kubectl explain AWSNodeTemplate command.
Here is an example that you can apply in your Kubernetes cluster:
apiVersion: karpenter.k8s.aws/v1alpha1
kind: AWSNodeTemplate
metadata:
name: default
spec:
subnetSelector:
karpenter.sh/discovery: karpenter
securityGroupSelector:
karpenter.sh/discovery: karpenter
tags:
karpenter.sh/discovery: karpenterWith this provider, we’ll only define which subnet the instances will be, which security groups the instance will be attaching, and the tags that it will wear. It will select the subnets and security groups wearing the tag karpenter.sh/discovery: karpenter. You can adapt the tags with whatever you already have on your infrastructure.
Provisioners
As we explained earlier, provisioners will help us define node sets in our cluster. First, we can define a really simple provisioner that will deploy inexpensive EC2 Spot instances in our Kubernetes cluster.
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: default
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
providerRef:
name: default
ttlSecondsAfterEmpty: 30This provisioner uses the default provider we defined earlier and will create Spot nodes that will be terminated 30 seconds after being empty.
With this, you already have a very robust autoscaling configuration. In this scenario, any unschedulable workload (eg. group of pods) will be handled by this provisioner and will be scheduled on a Spot instance that fits it and will be the least susceptible to be reclaimed.
Here is an example of a more specific provisioner:
apiVersion: karpenter.sh/v1alpha5
kind: Provisioner
metadata:
name: arm
spec:
requirements:
- key: karpenter.sh/capacity-type
operator: In
values: ["on-demand"]
- key: "kubernetes.io/arch"
operator: In
values: ["arm64"]
- key: topology.kubernetes.io/zone
operator: In
values: ["eu-west-3a"]
- key: karpenter.k8s.aws/instance-family
operator: In
values: ["t4g"]
taints:
- key: type
value: arm
effect: NoSchedule
labels:
type: arm
providerRef:
name: arm
ttlSecondsAfterEmpty: 30
ttlSecondsUntilExpired: 300This provisioner will be able to handle ARM workloads, with two conditions: each pod must have a nodeSelector pointing on the type: arm label and a toleration tolerating the type:arm=NoSchedule taint. The instances will be on-demand, part of the burstable Graviton family, and only created in the eu-west-3a availability zone.
The parameter combinations are infinite and you can specify all the specific needs for your workloads. To see all the configurations you can apply to provisioner, see the docs.
Workload scheduling example
Here is an example of a deployment that will create a pod that will be picked up and scheduled using this provisioner :
apiVersion: apps/v1
kind: Deployment
metadata:
name: inflate-arm
spec:
replicas: 3
selector:
matchLabels:
app: inflate-arm
template:
metadata:
labels:
app: inflate-arm
spec:
containers:
- name: inflate-arm
image: rancher/pause:3.2-arm64
resources:
requests:
cpu: 1
nodeSelector:
type: arm
tolerations:
- key: type
value: arm
effect: NoScheduleIf you apply this deployment to this cluster, here’s what will happen:
- The scheduler will try to schedule the 3 replicas of this application unsuccessfully
- Karpenter will match the pods’ requirements with all the provisioners it manages: the
armprovisioner will be a good fit - Karpenter computes an API call to the AWS EC2 service that will ask for:
- The least expensive
t4gon-demand instance that can handle a workload asking for 3 CPUs - Place it on the
eu-west-3aAZ
- The least expensive
- Karpenter creates a node in the Kubernetes cluster and affects the pod to this node
After all this, all there is to do is to wait for the node to join the Kubernetes cluster, and the 3 pods will be scheduled and running on the brand-new node.
I would give the configuration process a mark of 4/5 because the provider and provisioner configuration allows you to do a lot more things than Kubernetes Cluster Autoscaler does. However, I find it hard to gather all the possibilities from Karpenter’s documentation. You could be unaware of a feature that you need, but that is poorly referenced.
Operator experience
From an operator's point of view, Karpenter should be easy to maintain. The setup with the Cloud Provider (AWS in this case) is a one-time process and then the autoscaling magic happens inside Kubernetes.
Using GitOps tools such as ArgoCD to maintain provisioner and provider configuration should make Karpenter simple to manage.
Karpenter receives a lot of updates and new features at the moment. Be careful before updating it and read the changelogs, but it also makes the tool exciting to follow.
I would therefore give operator experience a 4/5 mark.
User experience
For discovery blog posts at Padok, we like to reflect on user experience when using a particular technology. However, for Karpenter, it’s not relevant as it’s not a tool destined to be used by end-users.
The user of any application or platform wouldn’t be aware that Karpenter manages autoscaling on the backend AWS Kubernetes clusters, let alone that the backend runs on Kubernetes.
Conclusion
All in all, Karpenter is a great replacement solution for Kubernetes Cluster Autoscaler if you are using AWS EKS. I personally find that moving the node scaling logic from the cloud provider into Kubernetes is a great DevX improvement.
However, we will need to wait for autoscaling use cases outside of AWS as it still lacks some integrations to be used across most cloud providers. But check out this documentation for best practices when setting up Karpenter on AWS EKS!
Topic | Rating
- Deployment: 4.5/5
- Configuration: 4/5
- Operator experience: 4/5
- User experience: N/A
- Final: 4/5