

Publié le 25 août 2022, mis à jour le 21 décembre 2023.
Hyperviseurs et automatisation
Tout d'abord, laissez-moi clarifier quelque chose : Dans cet article, je parlerai exclusivement du cycle de vie des VM. Et ce, pour une raison très simple : tous les services de Cloud Computing reposent sur les VM pour fonctionner. Certains services sont qualifiés de "sans serveur", comme les Lambdas d'AWS ou les Cloud Functions de Google, mais cela signifie seulement que le fournisseur de Cloud Computing gère ces serveurs à votre place. Le code doit bien tourner quelque part, non ? Les Cloud Functions de Google, par exemple, utilisent un framework appelé knative pour exécuter vos fonctions dans un cluster Kubernetes. Un cluster, qui a besoin de nœuds sur lesquels s'exécuter. Et vous l'avez deviné, ces nœuds... oui effectivement, ce sont des VM.
Comment et où ces VM fonctionnent-elles ? "Dans le Cloud" n'est pas une réponse acceptable.
Elles sont exécutées dans les centres de données des fournisseurs de Cloud, sur des serveurs physiques appelés Hyperviseurs : énormes machines dotées d'une grande puissance de calcul, construites et optimisées pour exécuter des machines virtuelles.
De nos jours, presque n'importe quelle machine est capable d'exécuter une machine virtuelle, et il est donc tout à fait possible de le faire sur son ordinateur portable. Il existe de nombreuses solutions logicielles pour ce faire, pour n'en citer que quelques-unes : Vagrant, kvm, Virtualbox, qemu... Si vous avez déjà utilisé une VM localement, vous savez qu'il peut y avoir plusieurs choses à configurer sur votre PC pour pouvoir utiliser une VM : créer un disque virtuel, créer une carte réseau virtuelle, configurer un réseau virtuel, connecter la VM à ce réseau, et peut-être transférer certains ports de votre réseau local vers votre VM.
Il s'agit là d'une configuration qui doit être effectuée "à l'extérieur" de la VM.Une fois cela fait, tous les autres composants avec lesquels la VM interagit doivent également être configurés : autoriser le trafic entrant par le biais de nouvelles règles de pare-feu, acheminer correctement le trafic vers la VM, attribuer une IP à la VM... Et enfin, vous pouvez vous connecter à votre VM et la configurer de l'intérieur.
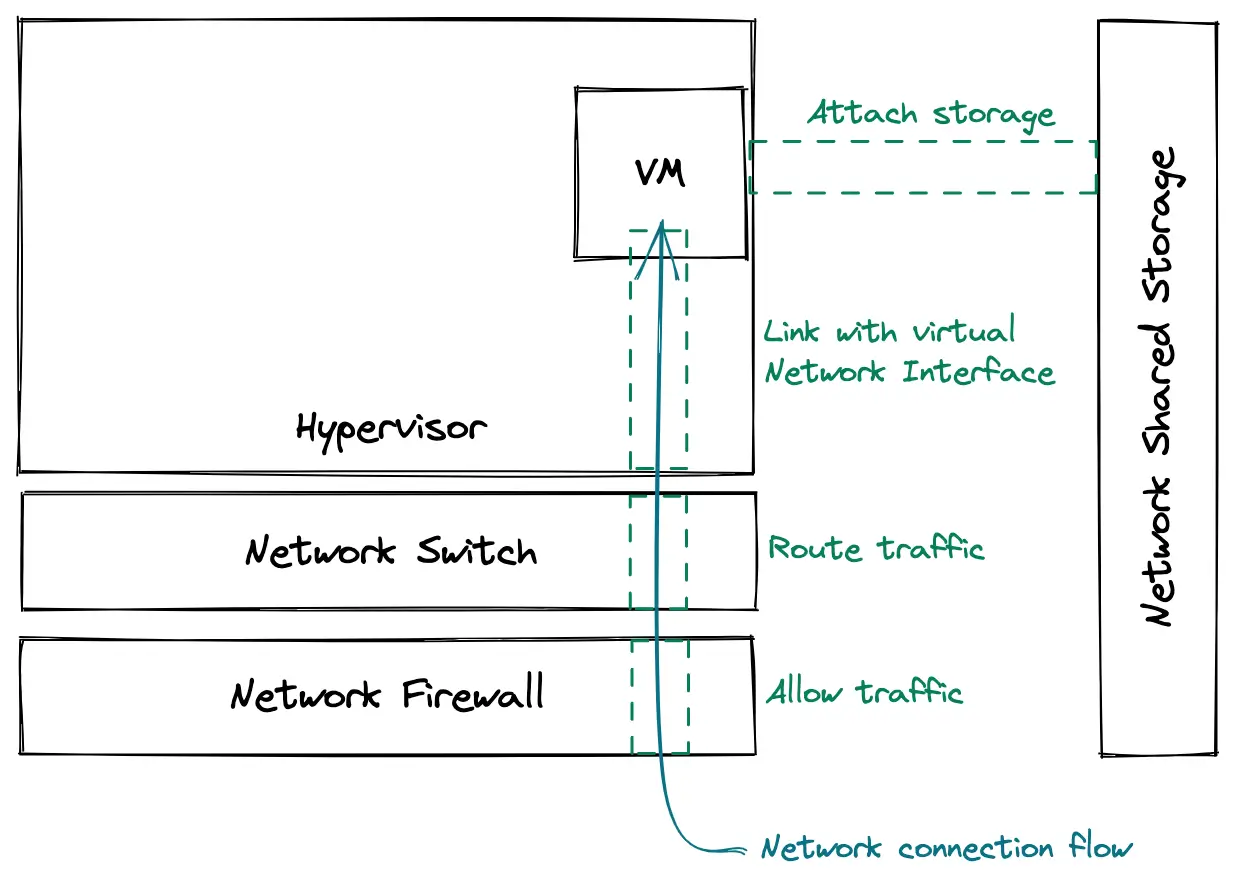
Toutes ces tâches peuvent être longues et fastidieuses à réaliser pour chaque VM, surtout si vous êtes un grand fournisseur de Cloud et que vous prévoyez d'exécuter des millions de VM dans le monde entier. C'est pourquoi, un haut niveau d'automatisation est également à l'origine de la magie qui consiste à fournir des VM à partir de rien.
Je n'entrerai pas dans le détail sur la manière dont les fournisseurs de Cloud automatisent tout cela dans cet article, mais si le sujet vous intéresse, allez consulter le projet Openstack, un logiciel libre permettant de construire et gérer son propre cloud privé.
Configuration au démarrage : cloud-init à la rescousse
Lorsque je demande une VM, elle est créée, préparée et son environnement est mis à jour pour qu'elle soit accessible et utilisable. À ce stade, la VM "existe" et est prête à démarrer. Une fois démarrée, elle est magiquement prête à être utilisée... n'est-ce pas ?
Eh bien, en quelque sorte. Mais lors du démarrage, une configuration supplémentaire se produit à l'intérieur de la VM. Par exemple, elle doit autoriser les connexions SSH à partir de clés SSH spécifiques.
Pour que la VM soit configurée à la fin du démarrage, il existe deux options :
- Indiquer à la VM comment elle doit se configurer de l'extérieur.
- Demander à la VM de déterminer elle-même sa configuration.
La deuxième option est la plus “évolutive”, et c'est celle qui est mise en œuvre chez tous les fournisseurs de Cloud. Pour y parvenir, l'outil cloud-init est très utile.
Qu'est-ce que cloud-init ? Eh bien, la description sur la page d'accueil est très explicite, donc je vous recommande d'y jeter un coup d'œil 😉 .
Pour faire simple, c'est un logiciel qui va initialiser une machine au démarrage, en configurant des choses comme le réseau, les périphériques de stockage, les clés SSH.... Il est également capable de récupérer sa configuration à partir de sources externes, ce qui le rend très polyvalent (nous y reviendrons un peu plus tard).
Si vous avez besoin de manipuler des outils pour comprendre leur fonctionnement, cet article vous guidera pour configurer une VM Vagrant afin de tester votre configuration cloud-init.
La documentation de cloud-init donne également un certain nombre d'exemples de configurations courantes, qui peuvent être très pratiques. Je vous laisse un exemple ci-dessous pour que vous ayez une idée du format !
# This is an example file to automatically configure resolv.conf when the
# instance boots for the first time.
manage_resolv_conf : true
resolv_conf:
nameservers: ['8.8.4.4', '8.8.8.8']
searchdomains:
- foo.example.com
- bar.example.com
domain: example.com
options:
rotate: true
timeout: 1Obtention des métadonnées
Vous l'avez probablement remarqué : lors du déploiement d'une VM, il ne vous a jamais été demandé de fournir un fichier de configuration cloud-init. Tout au plus, vous avez dû fournir un script de lancement pour votre instance, mais pas une description YAML complète de votre machine.
J'ai mentionné précédemment que cloud-init était capable de récupérer sa configuration à partir d'une source externe. Dans le Cloud, chaque fournisseur a des serveurs de métadonnées qui agissent comme source pour toutes les configurations de cloud-init (et bien plus encore !).
Ainsi, au démarrage, les machines virtuelles interrogent simplement le serveur de métadonnées et utilisent les informations obtenues pour se configurer. C'est très pratique, car cela signifie que chaque VM est configurée avec une interface standard, et que les métadonnées d'une VM peuvent être mises à jour par plusieurs sources :
- Les services IAM peuvent fournir des utilisateurs, des clés SSH ou des jetons de compte de service pour les VM.
- Les services réseau fourniront la configuration réseau appropriée
- Les utilisateurs peuvent fournir des scripts de lancement
La VM communique avec le serveur de métadonnées par HTTP et lui parle à une adresse IP spécifique : 169.254.169.254. Cette adresse IP est une adresse locale de liaison, qui est une plage d'adresses IP spéciale : aucun paquet envoyé vers, ou depuis cette plage n'est transmis par les routeurs du réseau. Tous les paquets restent dans le réseau local. C'est du moins le comportement par défaut de la plupart des routeurs.
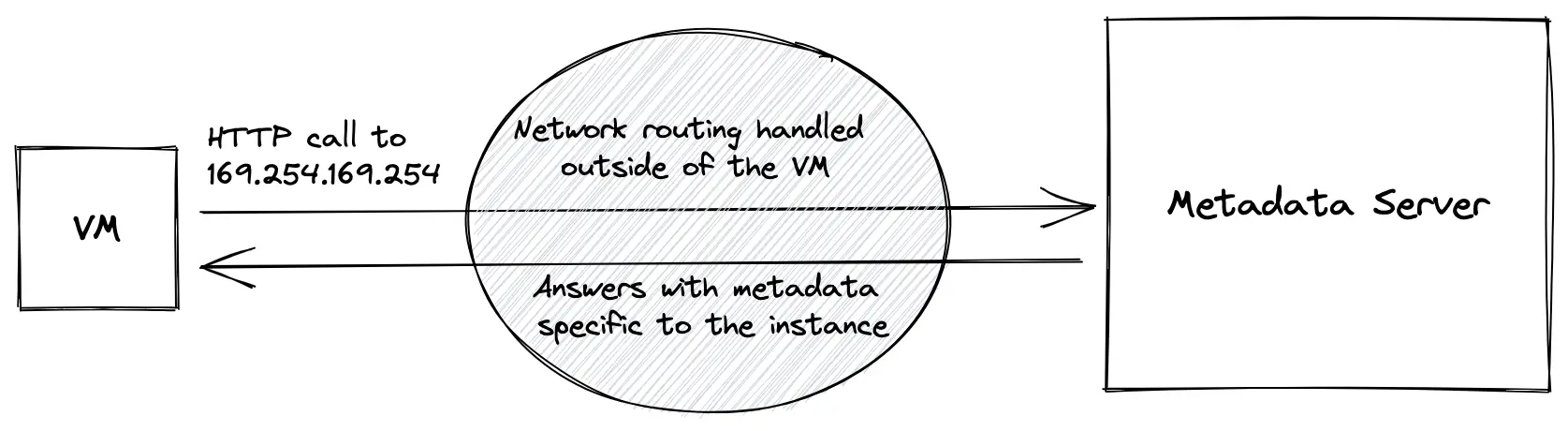
C'est la partie la plus "magique" de tout ce que nous avons vu aujourd'hui. Je soupçonne fortement les fournisseurs de Cloud d'avoir mis en place un routage spécial pour les paquets TCP envoyés à cette adresse IP spécifique, sinon ils n'atteindraient pas du tout le serveur de métadonnées.
Cette partie est une véritable boîte noire, elle n'est pas du tout documentée par Amazon, Google ou Microsoft, nous ne pouvons donc l'analyser que du point de vue d'une VM et essayer de faire de la rétro-ingénierie pour comprendre son fonctionnement interne.
La machine virtuelle communique avec le serveur de métadonnées via HTTP, sans fournir d'informations d'identification. Cela signifie que toute personne ayant accès au nœud peut lire ses métadonnées. Par exemple, sur GCP, vous pouvez faire tourner une VM et exécuter la commande suivante pour obtenir les balises de la VM :
# metadata.google.internal resolves to 169.254.169.254
curl "http://metadata.google.internal/computeMetadata/v1/instance/tags" -H "Metadata-Flavor: Google"Sans fournir aucune identification de votre VM, le serveur de métadonnées répond avec des informations spécifiques à votre VM uniquement ! Magique, n'est-ce pas ? Identifie-t-il votre VM via l'adresse MAC de la carte d'interface réseau virtuelle ? Ou via l'IP source ? Ce n'est pas clair et il s'agit probablement d'un "ingrédient secret" que les fournisseurs de Cloud ne divulgueront pas si facilement. Ce que nous savons, c'est qu'il n'est pas possible de récupérer les métadonnées d'une autre VM à partir d'une VM donnée.
Conclusion
J'espère que cette introduction à la façon dont les VM sont provisionnées dans une configuration Cloud vous a aidé à mieux comprendre les rouages et les coulisses de cette industrie.
Comme vous l'avez probablement remarqué, la façon dont le serveur de métadonnées identifie les machines virtuelles, ou comment le trafic est acheminé de la machine virtuelle au serveur de métadonnées, n'est toujours pas claire. Si vous avez des informations ou une hypothèse à partager, n’hésitez pas à nous en parler !